Chat stats with Spark & OpenLineage
Peter Hicks
Introduction
At oleander, we analyze conversations with our assistants Ollie and Lea to understand user patterns and improve our responses. As our user base grows, we want to understand the areas where we need to improve our coverage most.
We found it challenging to get all of the configuration correct for this setup. There are multiple layers of IAM permissions between the services, VPC assignments, and serverless EMR configuration idiosyncrasies to navigate. We've tried to highlight some of the main configuration hangups to help you get your Spark cluster running faster than we we're able to.
This tutorial demonstrates how to build a complete modern data pipeline using:
- EMR Serverless for distributed Spark processing
- Apache Iceberg for ACID transactions and time travel
- AWS Glue Data Catalog for metadata management
- Amazon Athena for interactive querying
- OpenLineage for comprehensive data observability
- Oleander for monitoring and lineage visualization
What we'll build
By the end of this tutorial, you'll have:
- A Spark job that ingests CSV data and creates Iceberg tables
- Word frequency analysis job
- Queryable tables in Athena with partition optimization
- Full data lineage tracking from source to analytics with oleander
Architecture overview
S3 CSVs → EMR Spark → Iceberg Tables → Glue Catalog → Athena Queries
EMR Serverless configuration
The following configuration sets up Spark with Iceberg support and OpenLineage integration. You can apply this via EMR Serverless application configuration or spark-submit:
Key configuration elements:
- Iceberg dependencies: Runtime JARs for Spark 3.5 and Iceberg
- Catalog setup: AWS Glue as the Iceberg catalog
- S3 integration: Warehouse location and file I/O
- OpenLineage settings: To enable oleander to do its magic
aws emr-serverless --region us-east-2 start-job-run \ --application-id <YOUR_APPLICATION_ID> \ --execution-role-arn <YOUR_ARN> \ --name "spark-with-iceberg" \ --job-driver '{ "sparkSubmit": { "entryPoint": "s3://oleander-demo-lake/scripts/spark-with-iceberg.py" } }' \ --configuration-overrides '{ "applicationConfiguration": [ { "classification": "spark-defaults", "properties": { "spark.jars.packages": "io.openlineage:openlineage-spark_2.12:1.39.0,org.apache.iceberg:iceberg-spark-runtime-3.5_2.12:1.9.2", "spark.jars.repositories": "https://repo1.maven.org/maven2", "spark.sql.extensions": "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions", "spark.sql.catalog.glue": "org.apache.iceberg.spark.SparkCatalog", "spark.sql.catalog.glue.warehouse": "s3://oleander-demo-lake/warehouse", "spark.sql.catalog.glue.catalog-impl": "org.apache.iceberg.aws.glue.GlueCatalog", "spark.sql.catalog.glue.io-impl": "org.apache.iceberg.aws.s3.S3FileIO", "spark.sql.defaultCatalog": "glue", "spark.extraListeners": "io.openlineage.spark.agent.OpenLineageSparkListener", "spark.openlineage.transport.type": "http", "spark.openlineage.transport.url": "https://oleander.dev", "spark.openlineage.transport.auth.type": "api_key", "spark.openlineage.transport.auth.apiKey": "<YOUR-OLEANDER-API-KEY>", "spark.openlineage.namespace": "spark-with-iceberg-demo", "spark.openlineage.appName": "oleander_ingest_csv_wordcount", "spark.openlineage.capturedProperties": "spark.sql.defaultCatalog" } } ] }'The complete PySpark pipeline
Our PySpark script handles the entire pipeline in a single, reproducible job.
- Data Ingestion: Read CSV files from S3
- Table Creation: Convert to Iceberg format with partitioning strategies
- JSON Processing: Parse conversation data and extract words
- Analytics: Compute word frequencies
- Persistence: Store results in queryable Iceberg tables
Note on Iceberg Partitioning:
Iceberg makes it easy to define partitioning strategies for your tables, such as partitioning chat conversations by date (e.g.,created_atday). This enables efficient query pruning—Athena and Spark can skip entire partitions when filtering by date, dramatically improving performance and reducing costs. Unlike traditional Hive-style partitioning, Iceberg handles partition evolution gracefully, so you can change partitioning schemes over time without rewriting your data. We are interested in rolling these up by day, which we accomplish in our Spark SQL.
Full pipeline script
# File: spark-with-iceberg.py# Complete pipeline for chat conversation analysisfrom pyspark.sql import SparkSession
CATALOG = "glue"DB = "oleander_demo"RAW = "s3://oleander-demo-lake/raw"
TBL_ORGS = f"{CATALOG}.{DB}.organizations"TBL_USERS = f"{CATALOG}.{DB}.users"TBL_CHATS = f"{CATALOG}.{DB}.chat_conversations"
ORGS_RAW = f"{RAW}/organizations.csv"USERS_RAW = f"{RAW}/users.csv"CHATS_RAW = f"{RAW}/chat_conversations.csv"
spark = SparkSession.builder.appName("oleander_ingest_csv_wordcount").getOrCreate()spark.sql(f"CREATE NAMESPACE IF NOT EXISTS {CATALOG}.{DB}")
# Step 1: Create temporary views from S3 CSV files# Using Spark's native CSV reader with proper options for JSON-containing fieldsspark.sql(f""" CREATE OR REPLACE TEMPORARY VIEW orgs_src USING csv OPTIONS (header 'true', inferSchema 'true', multiLine 'true', path '{ORGS_RAW}')""")spark.sql(f""" CREATE OR REPLACE TEMPORARY VIEW users_src USING csv OPTIONS (header 'true', inferSchema 'true', multiLine 'true', path '{USERS_RAW}')""")spark.sql(f""" CREATE OR REPLACE TEMPORARY VIEW chats_src USING csv OPTIONS ( header 'true', inferSchema 'true', multiLine 'true', escape '"', quote '"', mode 'PERMISSIVE', path '{CHATS_RAW}' )""")
# Step 2: Create Iceberg tables from CSV data# Using CTAS (Create Table As Select) with Iceberg format version 2# Partitioning chat conversations by day for efficient time-based queriesspark.sql(f""" CREATE OR REPLACE TABLE {TBL_ORGS} USING iceberg TBLPROPERTIES ('format-version'='2') AS SELECT CAST(id AS STRING) id, CAST(created_at AS TIMESTAMP) created_at, CAST(updated_at AS TIMESTAMP) updated_at, CAST(name AS STRING) name, CAST(plan_id AS STRING) plan_id, CAST(stripe_customer_id AS STRING) stripe_customer_id, CAST(stripe_subscription_id AS STRING) stripe_subscription_id FROM orgs_src""")
spark.sql(f""" CREATE OR REPLACE TABLE {TBL_USERS} USING iceberg TBLPROPERTIES ('format-version'='2') AS SELECT CAST(id AS STRING) id, CAST(created_at AS TIMESTAMP) created_at, CAST(updated_at AS TIMESTAMP) updated_at, CAST(name AS STRING) name, CAST(email AS STRING) email, CAST(password AS STRING) password, CAST(is_super AS BOOLEAN) is_super FROM users_src""")
spark.sql(f""" CREATE OR REPLACE TABLE {TBL_CHATS} USING iceberg PARTITIONED BY (days(created_at)) TBLPROPERTIES ('format-version'='2') AS SELECT CAST(id AS STRING) id, CAST(created_at AS TIMESTAMP) created_at, CAST(NULLIF(deleted_at,'') AS TIMESTAMP) deleted_at, CAST(organization_id AS STRING) organization_id, CAST(user_id AS STRING) user_id, CAST(preview AS STRING) preview, CAST(conversation AS STRING) conversation, -- raw JSON array string CAST(updated_at AS TIMESTAMP) updated_at FROM chats_src""")
# Step 3: Global word frequency analysis# Parse JSON conversation arrays, extract text, and compute word frequencies# with comprehensive stop-word filteringwordcount_sql = f"""WITH parsed AS ( SELECT id conversation_id, organization_id, user_id, created_at, from_json( conversation, 'array<struct<role:string,parts:array<struct<type:string,text:string>>>>' ) msgs FROM {TBL_CHATS}),msg_parts AS ( SELECT conversation_id, organization_id, user_id, created_at, m.role, p.text AS text FROM parsed LATERAL VIEW explode(msgs) m_tbl AS m LATERAL VIEW explode(m.parts) p_tbl AS p WHERE p.text IS NOT NULL),tokens AS ( SELECT conversation_id, organization_id, user_id, created_at, role, explode(split(lower(regexp_replace(text, '[^0-9a-zA-Z]+', ' ')), '\\\\s+')) AS word FROM msg_parts),filtered AS ( SELECT * FROM tokens WHERE word <> '' AND length(word) >= 2 AND NOT array_contains(array( 'the','a','an','and','of','to','in','for','on','at','is','are','it','this','that', 'with','as','be','by','or','from','but','if','then','so','we','you','i','they','he', 'she','them','our','us','your','my','their','was','were','do','did','does','can', 'could','should','would','about','not','no','yes','up','down','out','over','under', 'into','than','too','very','just','also','one','two','three' ), word))SELECT word, COUNT(*) AS countFROM filteredGROUP BY wordORDER BY count DESC, word ASCLIMIT 100"""
# Step 4: Organization and role-specific word analysis# Top 20 words per organization and role combination# Note: Spark SQL doesn't support QUALIFY, so we use ROW_NUMBER() with subqueriesper_org_role_sql = f"""WITH parsed AS ( SELECT id conversation_id, organization_id, user_id, created_at, from_json(conversation,'array<struct<role:string,parts:array<struct<type:string,text:string>>>>') msgs FROM {TBL_CHATS}),msg_parts AS ( SELECT conversation_id, organization_id, user_id, created_at, m.role, p.text AS text FROM parsed LATERAL VIEW explode(msgs) m_tbl AS m LATERAL VIEW explode(m.parts) p_tbl AS p WHERE p.text IS NOT NULL),tokens AS ( SELECT organization_id, role, explode(split(lower(regexp_replace(text,'[^0-9a-zA-Z]+',' ')),'\\\\s+')) AS word FROM msg_parts),filtered AS ( SELECT * FROM tokens WHERE word <> '' AND length(word) >= 2),counts AS ( SELECT organization_id, role, word, COUNT(*) AS cnt FROM filtered GROUP BY organization_id, role, word),ranked AS ( SELECT organization_id, role, word, cnt, ROW_NUMBER() OVER (PARTITION BY organization_id, role ORDER BY cnt DESC, word ASC) rn FROM counts)SELECT organization_id, role, word, cnt AS countFROM rankedWHERE rn <= 20ORDER BY organization_id, role, count DESC, word ASC"""
# Step 5: Persist analytics results as Iceberg tables# Creating permanent tables for downstream consumptionWC_GLOBAL_TBL = f"{CATALOG}.{DB}.word_counts_global"WC_BY_ORG_ROLE_TBL = f"{CATALOG}.{DB}.word_counts_by_org_role"
spark.sql(f""" CREATE OR REPLACE TABLE {WC_GLOBAL_TBL} USING iceberg TBLPROPERTIES ('format-version'='2') AS {wordcount_sql}""")
spark.sql(f""" CREATE OR REPLACE TABLE {WC_BY_ORG_ROLE_TBL} USING iceberg PARTITIONED BY (organization_id, role) TBLPROPERTIES ('format-version'='2') AS {per_org_role_sql}""")
# Step 6: Iceberg table maintenance (optional but recommended)# Manage snapshots, compact small files, and clean up old metadataspark.sql(f"CALL {CATALOG}.system.snapshots('{DB}.chat_conversations')").show(truncate=False)try: spark.sql(f"CALL {CATALOG}.system.rewrite_data_files(table => '{DB}.chat_conversations')").show(truncate=False) spark.sql(f"CALL {CATALOG}.system.expire_snapshots(table => '{DB}.chat_conversations', older_than => TIMESTAMPADD('HOURS', -1, CURRENT_TIMESTAMP()))").show(truncate=False)except Exception as e: print(f"[maintenance skipped] {e}")
print("Done.")Querying your data with Athena
With our Iceberg tables registered in the Glue Data Catalog, we can now query them using Athena. The tables benefit from:
- Schema evolution: Iceberg handles schema changes gracefully
- ACID transactions: Consistent reads even during concurrent writes
- Time travel: Query historical versions of your data
- S3 Bookkeeping: All the Athena query history and metadata are written to S3
Example queries
-- Count rows ingestedSELECT (SELECT count(*) FROM glue.oleander_demo.organizations) AS orgs, (SELECT count(*) FROM glue.oleander_demo.users) AS users, (SELECT count(*) FROM glue.oleander_demo.chat_conversations) AS chats;
-- Global word counts (top 50)SELECT word, countFROM glue.oleander_demo.word_counts_globalORDER BY count DESC, word ASCLIMIT 50;
-- By org, role (sample top)SELECT organization_id, role, word, countFROM glue.oleander_demo.word_counts_by_org_roleWHERE organization_id = 'org_01234567-89ab-cdef-0123-456789abcdef'ORDER BY role, count DESCLIMIT 100;Time travel queries
One of Iceberg's powerful features is time travel - querying data as it existed at a specific point in time:
-- Query conversations from a specific timestampSELECT * FROM glue.oleander_demo.chat_conversationsFOR SYSTEM_TIME AS OF TIMESTAMP '2024-01-15 10:00:00';
-- Query using a specific snapshot IDSELECT * FROM glue.oleander_demo.chat_conversationsFOR SYSTEM_VERSION AS OF 1234567890;Query results
Here are the top words found in our chat conversations from one of our development environments, available within Athena and also printed by our Spark SQL script:
| Word | Count |
|---|---|
| namespace | 225 |
| job | 207 |
| last | 142 |
| execution | 97 |
| 30 | 93 |
| days | 92 |
| counts | 65 |
| grouped | 57 |
| get | 54 |
| data | 47 |
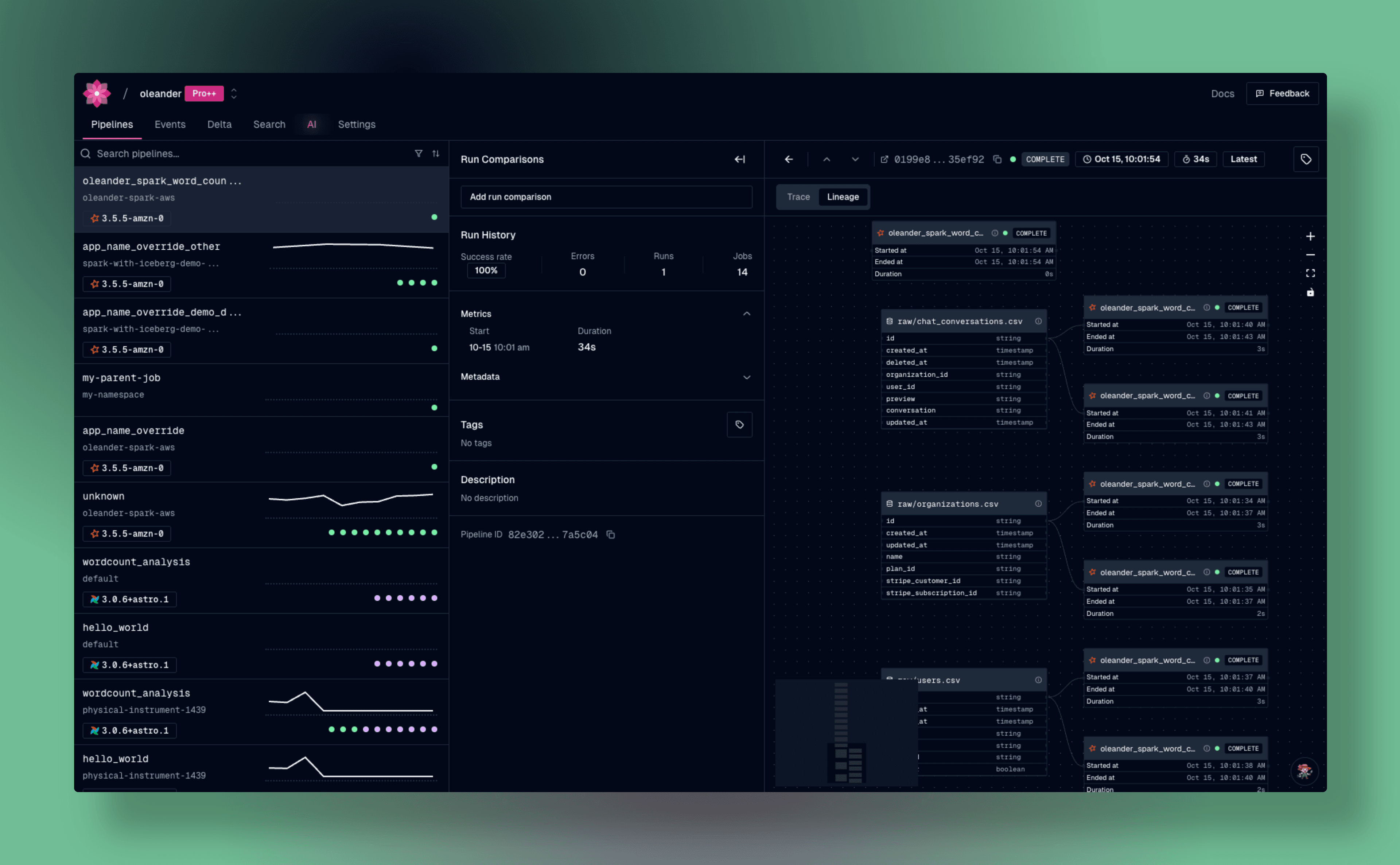
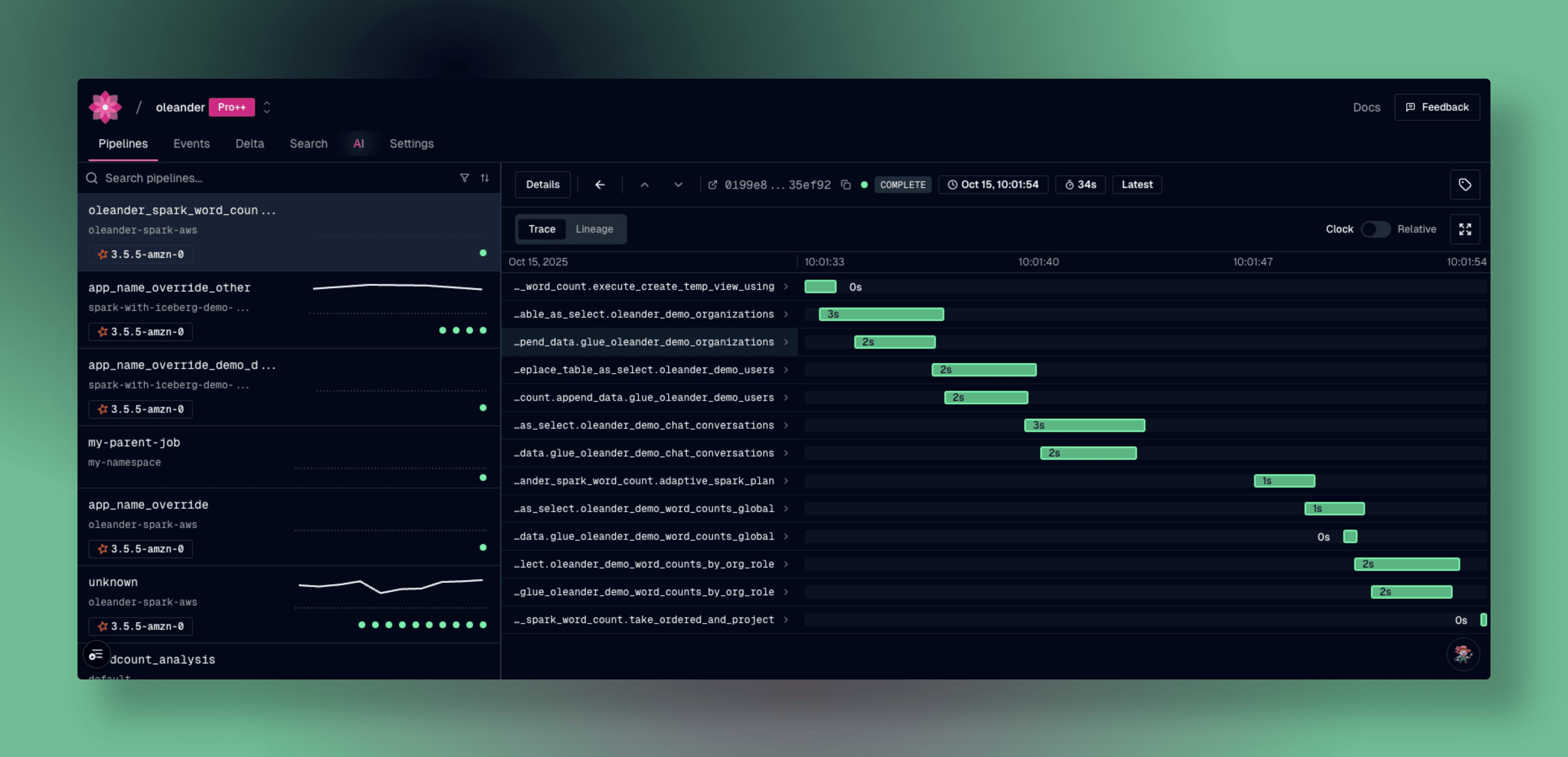
Checking upon oleander
Our OpenLinege metadata has now arrived at oleander and is available in our pipelines view and events pages. It includes derived lineage, plan analysis, task runs within the pipeline and more. The Spark integration has been in the works for several years now and we're delighted to be able to bring the richness of it to life. Let us know what you think!